THE CRISP-DM METHODOLOGY ⌨️
In data science, projects usually starts by an inquiry from business people that are sent to Data or IT department to begin with the development of the product that fits the requeriments. After data, the chief of staff talks with their team and communicate the demand to their data scientist. So later, is very common, mostly for junior data scientist to start the development of a funcy machine learning / deep learning model that magically solve the problem that business needs. Actually, this is a hugh mistake. Because in 99% of the cases, this rapid model just don't fit the requirement because it was build without answering the right questions. This is why the scientific method came in place to follow the process of objectively establishing facts through testing and experimentation. The basic process involves making an observation, forming a hypothesis, making a prediction, conducting an experiment and finally analyzing the results.
If we extrapolate the methodology to the life cycle of data science projects, we can establish the following stages:
Understand in detail the objectives of the project: this first stage includes meeting with the customers (managers and experts of the company) and discussing and knowing in detail the goals of the project.
Collect the available data and information: it can be provided by the client databases, APIs, files or through surveys, etc. In this stage, we look forward to arriving at a clear understanding of all information.
Establish the hypotheses to be tested, working models, possible theories, and methodologies to use.
Estimate and validate previously established models. Contrast the hypotheses formulated.
Obtain preliminary conclusions.
Discuss previous conclusions with the client and reconsider the objectives if necessary.
Final conclusions and decision-making.
What is the CRISP-DM methodology?
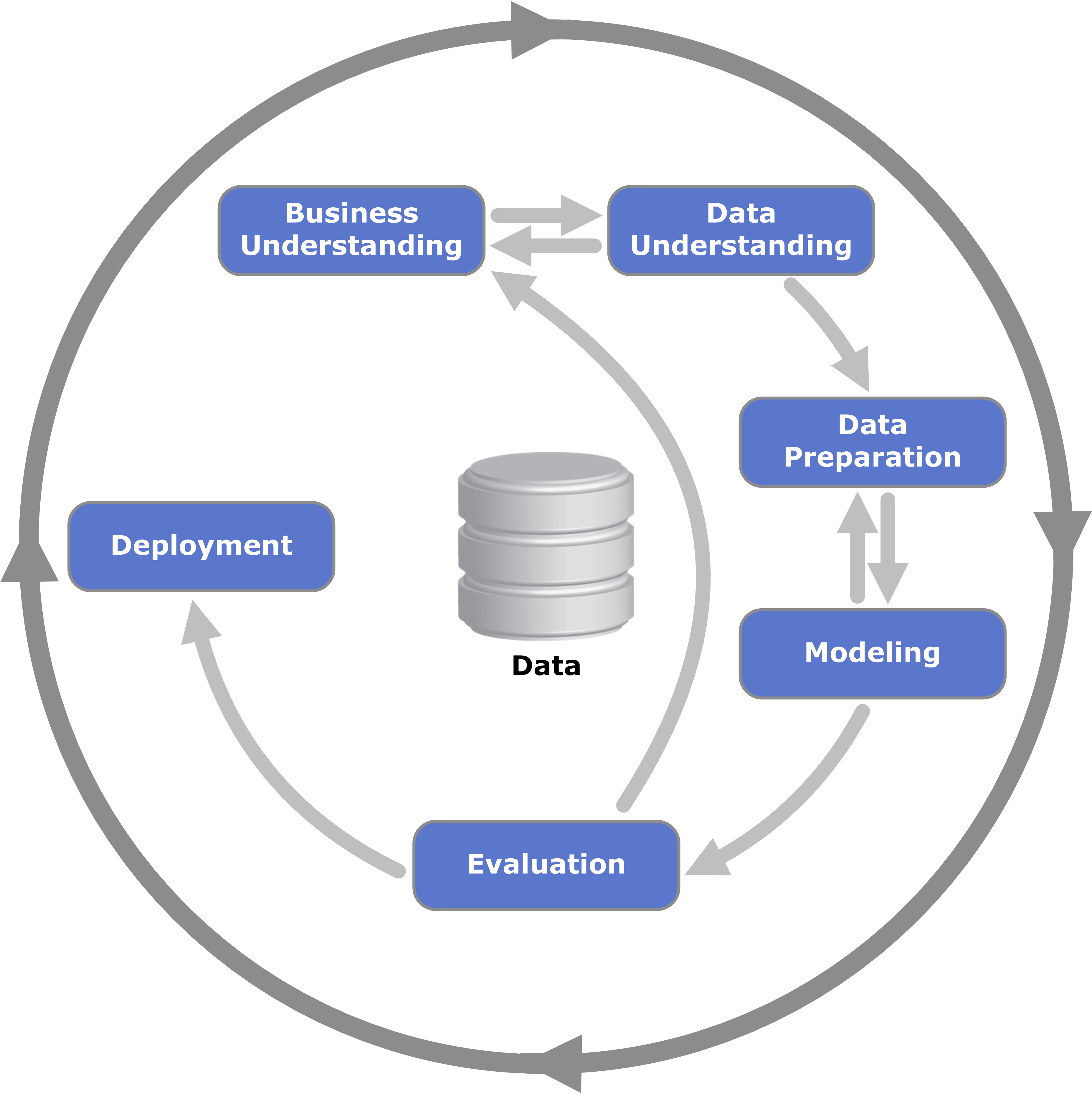
The CRISP-DM method was developed by IBM (which includes IBM SPSS Statistics and other products) and consists of a set of stages, so that at each stage you can go back to the previous one and improve the process. The procedure takes into account not only the understanding and needs of the client and the business, but also the scientific part of the data analysis. The sequence of the phases is not rigid. Moving back and forth between different phases is always required. The outcome of each phase determines which phase, or particular task of a phase, has to be performed next. The arrows indicate the most important and frequent dependencies between phases.
“The scientific method trains the brain to examine and observe before making and statement of fact”
The stages are:
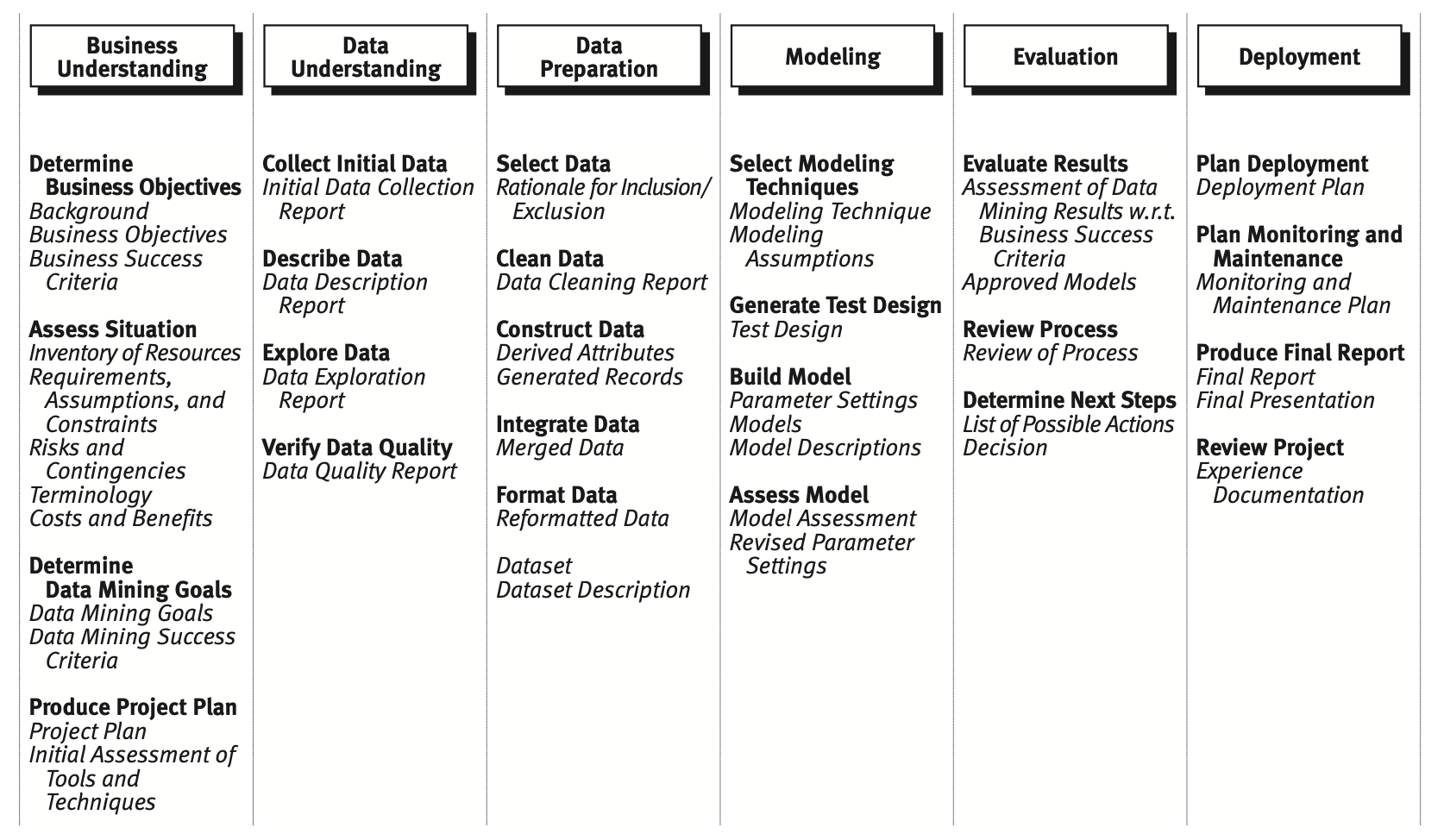
- Business Understanding: In the first step, you need to pay attention to identifying the problem. You should identify the metrics used to measure success over baseline, which is the same as doing nothing. Secondly, the identification of the type of problem we are facing. Thirdly, identify key people within your organization and outside that will help you on the data science project. Fourthly, get the specifications, requirements, priorities, and budgets of the project. You need to know how accurate the solution needs to be. In addition, you should analyze if you should be built internally versus using vendor solutions. If a vendor is a solution, do a vendor comparison and checked their benchmark.
- Data Understanding: The data understanding phase starts with initial data collection and proceeds with activities that enable you to become familiar with the data, identify data quality problems, discover first insights into the data, and/or detect interesting subsets to form hypotheses regarding hidden information.
- Data Preparation: The data preparation phase covers all activities needed to construct the final dataset [data that will be fed into the modeling tool(s)] from the initial raw data. Data preparation tasks are likely to be performed multiple times and not in any prescribed order. Tasks include table, record, and attribute selection, as well as transformation and cleaning of data for modeling tools.
- Data Modeling: In this phase, various modeling techniques are selected and applied, and their parameters are calibrated to optimal values. Typically, there are several techniques for the same data mining problem type. Some techniques have specific requirements on the form of data. Therefore, going back to the data preparation phase is often necessary.
- Evaluation: At this stage in the project, you have built a model (or models) that appears to have high quality from a data analysis perspective. Before proceeding to final deployment of the model, it is important to thoroughly evaluate it and review the steps executed to create it, to be certain the model properly achieves the business objectives. A key objective is to determine if there is some important business issue that has not been sufficiently considered. At the end of this phase, a decision on the use of the data mining results should be reached.
- Deployment: Creation of the model is generally not the end of the project. Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized and presented in a way that the customer can use it. It often involves applying “live” models within an organization’s decision-making processes—for example, real-time personalization of Web pages or repeated scoring of marketing databases. Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process across the enterprise. In many cases, it is the customer, not the data analyst, who carries out the deployment steps. However, even if the analyst will carry out the deployment effort, it is important for the customer to understand up front what actions need to be carried out in order to actually make use of the created models.
I would like to mention that there are two other basic methodologies: SEMMA and KDD. The methodology called SEMMA was proposed by the SAS Institute, and consists of the stages of Sample, Explore, Modify, Model, and Assess. On the other hand, the KDD (Knowledge Discovery in Databases) methodology refers to the process of finding knowledge in data and emphasizes the high-level application of data mining methods.
References
[1] Gavin Wright, Scientific Method, https://www.techtarget.com/whatis/definition/scientific-method#:~:text=The%20scientific%20method%20is%20the,and%20finally%20analyzing%20the%20results.
[2] IBM, CRISP-DM v0.1